




 PDF
PDF Продолжая разговор, об упрощении дерева запроса, начатый в предыдущем посте, рассмотрим еще один интересный случай упрощения.
Продолжая разговор, об упрощении дерева запроса, начатый в предыдущем посте, рассмотрим еще один интересный случай упрощения.
В качестве тестовой БД все та же база opt из предыдущего поста.
Запрос:
use opt; go select * from t1 where t1.c in (select t2.b from t2 where t2.c = 10 and t2.b = t1.c); -- 1. select * from t1 where t1.c in (select t2.b from t2 where t2.c = 10 and t1.c = t2.b); -- 2.
План:

На первый взгляд, даже не сразу понятно, в чем разница между запросами и между планами.
Обратите внимание на предикаты: в первом запросе это t2.b = t1.c, во втором t1.c = t2.b. Т.е. мы просто поменяли местами колонки в сравнении.
Обычно, даже в не декларативных языках программирования, не имеет значения с какой стороны от операции сравнения стоят операнды, в декларативном языке, это не должно иметь значения и подавно. Однако, по иронии судьбы, именно декларативность языка первопричина разницы в планах.
Создавая запрос, мы описываем, что мы хотим получить, но как мы это получим — решает оптимизатор. На основе запроса он строит логическое дерево операторов, упрощает его и генерирует план.
Именно на этапе упрощения появляется разница, которая приводит к разнице в планах.
Для первого запроса строится дерево логических операторов, после этого начинается этап упрощения, на котором, среди прочих действий, происходит поиск и исключение избыточных условий. Если, например, написать where a = 1 and a = 1, оптимизатор исключит одно избыточное условие, при этом не важно, будет ли написано where a = 1 and a = 1 или where a = 1 and 1 = a. Однако, при раскрытии подзапроса в in этого не происходит, видимо, не предусмотрели.

В результате, просто потому, что нет прямого совпадения, условие остается и не исключается.
После упрощения, дерево логических операторов выглядит следующим образом:

Для второго запроса, поскольку мы поменяли порядок следования колонок в предикате вручную, теперь совпадение есть.

Избыточное условие исключается на этапе упрощения.
В результате, дерево логических операторов после упрощения содержит всего одно условие и выглядит так:

То же самое происходит и с запросом:
select * from t1 where t1.c = some(select t2.b from t2 where t2.c = 10 and t2.b = t1.c) select * from t1 where t1.c = some(select t2.b from t2 where t2.c = 10 and t1.c = t2.b)
Два разных дерева для одного и того же, по сути, запроса приводят к разным планам.
В данном простом примере, влияния на производительность нет или оно минимально, но если взять немного другой пример, в котором задействовано исключение джойнов, разница будет видна невооруженным глазом.
Используется БД AdventureWorks2008.
use AdventureWorks2008; go set showplan_xml on go select * from Sales.SalesOrderHeader soh where soh.CustomerID in (select sc.CustomerID from Sales.Customer sc where sc.CustomerID = soh.CustomerID) go select * from Sales.SalesOrderHeader soh where soh.CustomerID in (select sc.CustomerID from Sales.Customer sc where soh.CustomerID = sc.CustomerID) go set showplan_xml off go
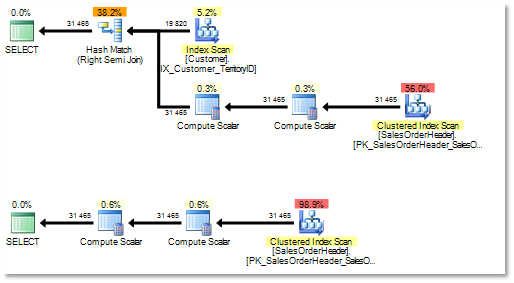
В первом случае упрощения не произошло, остается лишний скан таблицы, плюс блокирующий и потребляющий память Hash Join.
Итог
Для проверки входит ли элемент в некое множество, можно использовать оператор exists. Очень часто возникает много вопросов, что лучше или быстрее in (select …) или exists (select …).
Обычно оптимизатор почти всегда строит одинаковый план для обеих конструкций, и одинаково выполняет эти запросы. Однако, в рассматриваемом нами случае, план будут разными, т.к. в случае использования exists оптимизатор получает на вход другое дерево операторов для упрощения, в котором нет описанных выше проблем.
Кроме того, есть такая вещь как привычка, привыкши писать in, очень легко написать not in, когда потребуется проверить, что элемент не входит во множество. В такой постановке вопроса not in и not exists начинают отличаться, в случае если в подзапросе могут быть null.
По перечисленным выше причинам я почти всегда стараюсь использовать оператор exists.




