




 PDF
PDF
Введение
На прошедшем мероприятии SQLSaturday #261 — Moscow 2013 я рассказывал о том, как оптимизатор оценивает предполагаемое число строк и на основании этого строит план запроса. Иными словами я говорил про оценки кардинальности, и разумеется, не смог обойти вниманием новую версию механизма оценки кардинальности в SQL Server 2014.

Информации на эту тему пока довольно мало, в конце заметки я приведу список всех известных мне на сегодня статей на эту тему. Информации из первоисточников пока нет вовсе, надеюсь, с официальным выходом SQL Server 2014 ситуация изменится в лучшую сторону.
Пока же, я хочу поделиться с читателями результатами своих собственных экспериментов.
Общее описание процесса оценки кардинальности
В некоторых предыдущих постах я уже описывал общий процесс оценки кардинальности, но на всякий случай, приведу еще раз краткое описание.
Процесс начинается на самой ранней стадии обработки запроса, еще до того, как начнется фактический поиск вариантов плана. Когда запрос приходит на сервер он разбирается в дерево логических операторов. Узлы этого дерева — объекты определенных классов, которые отражают логику запроса.
Рассмотрим простой пример, для которого, я по-прежнему, использую суррогатную простую БД opt из заметки Оптимизатор (ч.1): Введение, Optimization: Simplification.
Посмотрим на план следующего запроса.
use opt; go select * from t1 where b = 100 option(recompile, querytraceon 8606, querytraceon 8612, querytraceon 3604, querytraceon 9130);
В запросе используются недокументированные флаги трассировки, описание каждого из них вы можете найти в предыдущем цикле заметок Оптимизатор (ч.1, 2, 3, 4).
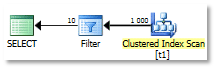
На вкладке Messages можно увидеть деревья логических операций:
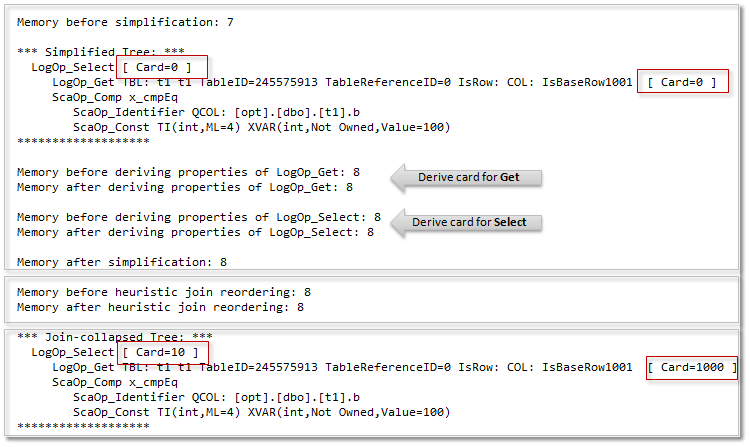
Simplified Tree — дерево операторов после упрощения. Оператор LogOp_Select имеет значение реляционной операции select, т.е. «выбрать из» и соответствует оператору фильтра в плане. Оператор LogOp_Get — представляет собой операцию получения таблицы, соответствует оператору Clustered Index Scan в плане. Обратите внимание на свойство Card (кардинальность), для каждого логического оператора — оно равно нулю (0).
Далее для операторов вычисляются некоторые свойства (derive property), в данном случае кардинальность.
После этого, начинается фаза поиска изначального порядка соединений, на основе эвристических алгоритмов (в запросе нет соединений, тем не менее формально фаза присутствует в процессе).
Join-Collapsed Tree — дерево после удаления избыточных соединений.
Обратите внимание, в этом дереве для каждого логического оператора кардинальность посчитана.
Это не единственное место, где оценивается кардинальность, в дальнейшем, при поиске плана, оптимизатор генерирует альтернативы текущему дереву операторов и получает новые логические группы, для них также должна быть произведена оценка кардинальности.
В целом, процесс выглядит так (слева направо):
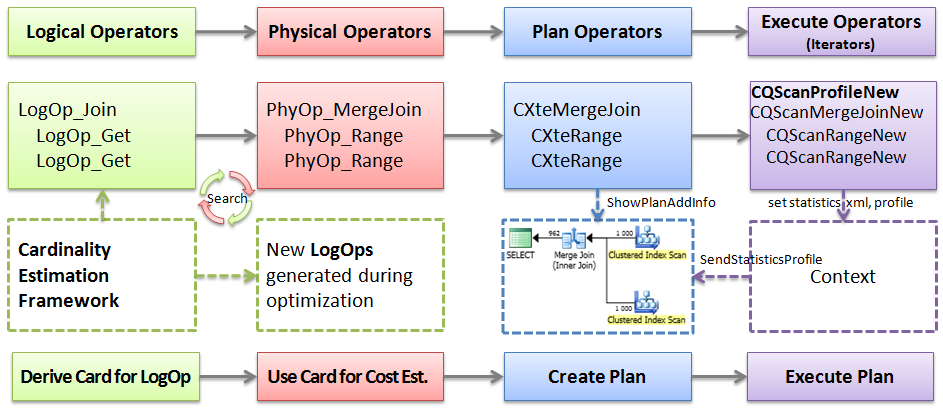
- Дерево логических операторов — TF 8606
- Дерево физических операторов — TF 8607
- Дерево операторов плана (то что находится в кэше, и что мы привыкли называть скомпилированным планом) — опосредованно, через ShowPlan
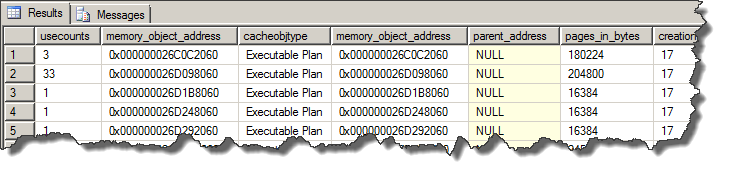
- Дерево исполняемых операторов (также их называют «итераторы», т.е. те операторы, которые совершают непосредственные итерации по строкам) — это дерево нельзя посмотреть никак, кроме как использовать debugger. То что мы видим как actual execution plan, на самом деле комбинация собранной при помощи специального итератора CQScanProfileNew профилировочной информации, с тем планом, что был скомпилирован. Это дерево генерируется для каждого пользователя, если один и тот же запрос, с одним и тем же скомпилированным планом выполняют несколько пользователей одновременно. Можно посмотреть факт его наличия и несколько параметров, например количество использований, размер и т.д.
select cpdo.*, mo.* from sys.dm_exec_cached_plans cp cross apply sys.dm_exec_cached_plan_dependent_objects(cp.plan_handle) cpdo join sys.dm_os_memory_objects mo on mo.memory_object_address = cpdo.memory_object_address
Оценка кардинальности выполняется на самых ранних этапах оптимизации и участвует во всех формулах вычисления стоимости, а значит имеет огромное влияние на выбор плана. Поэтому важно знать, как она выполняется.
Оценка кардинальности для версий до 2014
Кардинальность начинает вычисляться с самых нижних узлов дерева, постепенно на основе вычисленной кардинальности нижних узлов, вычисляется кардинальность следующих и т.д. пока процесс не дойдет до вершины.
Внутри узла, принимается во внимание контекст логического оператора, который представляет узел (например, для фильтра это будет один алгоритм вычисления, для внутреннего соединения — другой, для внешнего соединения — третий и т.д.). Используя выбранный алгоритм и поступающую на вход статистическую информацию дочерних узлов (в данном примере дочерний узел — это базовая таблица, по этому берется базовая статистика таблицы) , оптимизатор вычисляет селективность оператора. Полученную селективность он умножает на окружающую кардинальность (также полученную из предыдущих вычислений для дочернего узла, т.е. в данном случае, базовой таблицы).
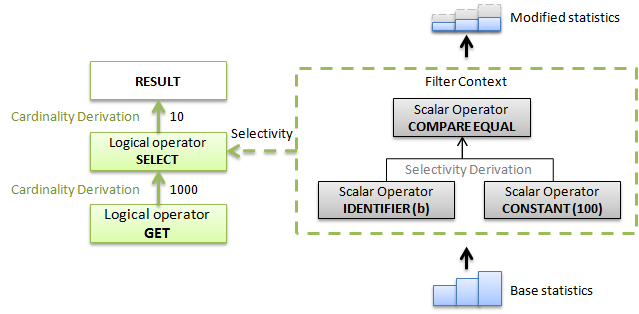
Процесс идет немного по-другому, если оптимизатор заранее знает какое число строк ему необходимо получить, т.е. имеет некое целевое число строк (row goal). Это бывает, например, в случае, когда используется оператор TOP. В таком случае, оценка кардинальности, производимая снизу, ограничивается целевым числом строк сверху.
select top(5) * from t1 where b = 100

Оценка кардинальности 2014
Общий процесс вычислений не изменился, по-прежнему используется подход снизу вверх, вероятностная модель для вычисления селективности, разные алгоритмы для разных операторов. Однако, изменились и добавились сами алгоритмы, которые теперь выступают в виде некоторых абстракций, реализованных при помощи классов, называемых калькуляторами. Два основных типа калькулятора, которые я нашел, это Selectivity Calculator (CSelCalc…) — вычисление селективности, и Distinct Value Calculator (CDVC…) — вычисление числа уникальных значений. Кроме того, калькуляторы делятся по типам операторов к которым применяются (например, для фильтров, для соединений и т.д.).
К нашему удовольствию, в 2014, мы можем увидеть процесс и некоторые подробности вычисления в действии. Для этого есть расширенное событие query_optimizer_estimate_cardinality. Оно уже достаточно неплохо описано несколькими статьями в интернете ребятами из sqlskills, я приведу в конце заметки эти ссылки.
Однако, мне больше нравится способ с использованием недокументированного флага трассировки, это быстрее и проще, кроме того, используя его совместно с другими флагами, можно увидеть процесс в целом. Можно комбинировать оба способа, чтобы получить более полную картину.
Я думаю, не нужно напоминать, о недопустимости недокументированных флагов на production серверах =).
TF 2363
Добавим этот флаг в предыдущий запрос, и посмотрим на то же самое место где вычислялись свойства операторов LogOp_Get и LogOp_Select:

Для оператора Get, вычислять особо нечего, т.к. нужно просто получить данные о кардинальности базовой таблицы, а вотдля оператора Select (фильтра), нужно посчитать число возвращаемых строк. Видим интригующее начало Begin selectivity computation.
Я скопировал вывод этого дерева и сопоставил с картинкой из предыдущей части, чтобы показать, что есть что в дереве и на картинке.
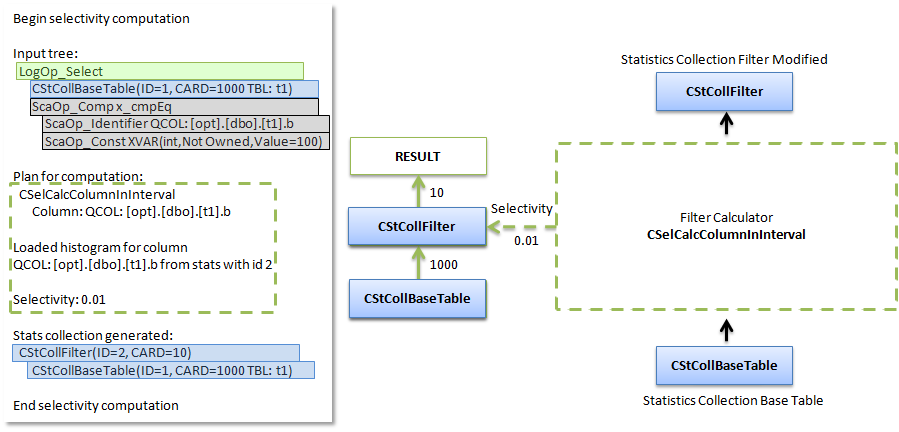
Входное дерево (Input Tree) — копирует структуру дерева логических операторов, за исключением того, что место оператора LogOp_Get уже занимает коллекция статистик базовой таблицы (CStCollBaseTable — Statistics Collection Base Table).
План для вычисления (Plan For Computation) — калькулятор, которым будем считать селективность предиката внутри фильтра. Кроме того, указывается, какая гистограмма была для этого загружена.
Если по мнению оптимизатора селективность была посчитана неверно, он может сделать перепланировать вычисление (Replanning) и использовать другой калькулятор.
Сгенерированное дерево статистик (Stats collection generated) — дерево статистик, которое получилось в результате вычисления. Как видно, результатом вычисления фильтра стала кардинальность и выходная статистика. В данном случае, запрос очень простой и фильтр самый верхний узел, но если бы выше были другие операторы, то они бы уже использовали коллекцию статистик сгенерированных для фильтра и т.д..
Этот процесс хорошо помогает понять, почему ошибка в оценке имеет свойство накапливаться от оператора к оператору по мере продвижения к вершине.
Теперь посмотрим на то, как оценка кардинальности выполняется не только для базового дерева, но и в процессе исследования новых логических групп (альтернативных планов) в процессе оптимизации.
Для этого возьмем более сложный пример с соединениями и группировкой. Получим план следующего запроса:
select distinct t1.b, t2.b from t1 join t2 on t2.b = t1.b where t1.b < 300 option(recompile, merge join , querytraceon 3604 -- <-- Output to Console , querytraceon 8606 -- <-- Show LogOp Trees , querytraceon 8619 -- <-- Show Applied Transformation Rules , querytraceon 8612 -- <-- Add Extra Info to the Trees Output , querytraceon 2372 -- <-- Memory for Phases , querytraceon 2373 -- <-- Memory for Deriving Properties , querytraceon 2363 -- <-- (2014, new:) TF Selectivity );
Запрос имеет следующий план:
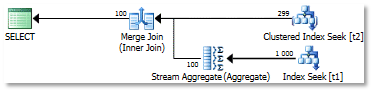
Два слова о том, что происходит согласно плану запроса.
Поскольку в запросе мы используем distinct, т.е. говорим серверу — отбери нам уникальные записи — сервер использует операцию агрегации (или проще — группировку), но только по одному из полей t1.b, т.к. поле t2.b — это первичный ключ, следовательно оно уникально, группировать смысла нет.
Второй момент, мы не видим здесь оператора фильтра для условия where, дело в том, что этот оператор был совмещен с оператором сканирования и отображается в операторе сканирования в свойстве residual predicate. Если в предыдущем простом запросе убрать флаг 9130, то оператор фильтра также будет совмещен со сканированием. Это происходит на более позднем этапе, чем этап оптимизации. Вспомним картинку деревьев, дерево 2 — физические операторы (но еще не план), дерево 3 — операторы плана (план). Процесс, который преобразует дерево физических операторов в дерево операторов плана, называется Post Optimization Rewrite. Этот процесс выполняет некоторые трансформации, например top + sort -> top sort, или в данном случае, помещает фильтр в сам оператор сканирования.
Третий момент, операция группировки по колонке t1.b помещена под операцию соединения, поскольку выгодно сгруппировать строки до соединения, чтобы соединять меньшее число строк.
Дерево логических операторов имеет следующий вид:
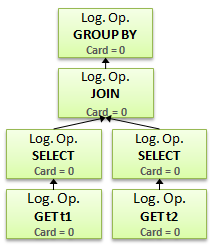
Получение двух таблиц, фильтр по двум таблицам (поскольку мы фильтруем по той же колонке, что и соединяем, фильтр может распространиться на колонки обеих таблиц), соединение и группировка. Т.е. все так, как мы описали в запросе — группировка идет после соединения ( в плане же, она идет перед соединением).
Посмотрим, как вычисляется кардинальность и как проходит процесс оптимизации. Вы можете наблюдать вывод недокументированных флагов трассировки и сопоставлять их с картинками ниже, которые я составил глядя на этот вывод (или просто смотреть на картинки, если вы мне доверяете =)):
1. Входное дерево, загружаем информацию о статистиках базовой таблицы

2. Применяем знакомый нам по предыдущему запросу калькулятор для фильтра, вычисляем кардинальность по t1
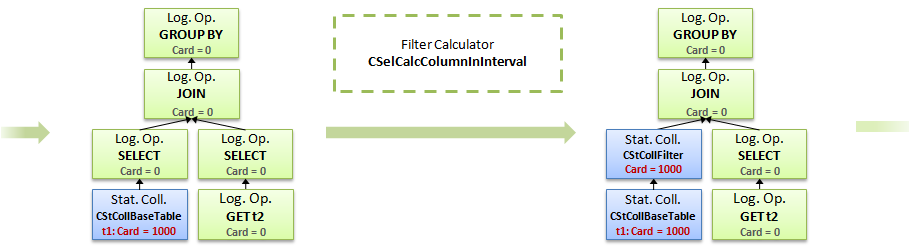
3. Загружаем информацию по второй таблице и колонке
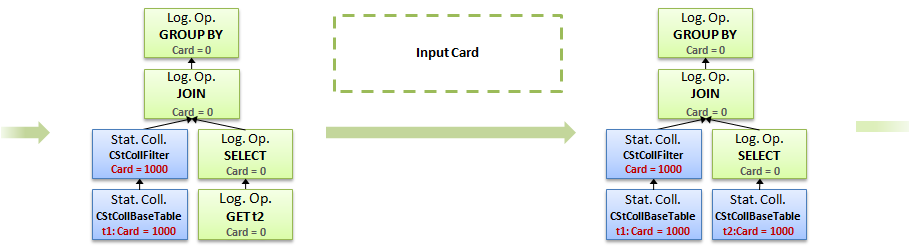
4. Применяем такой же калькулятор к ней
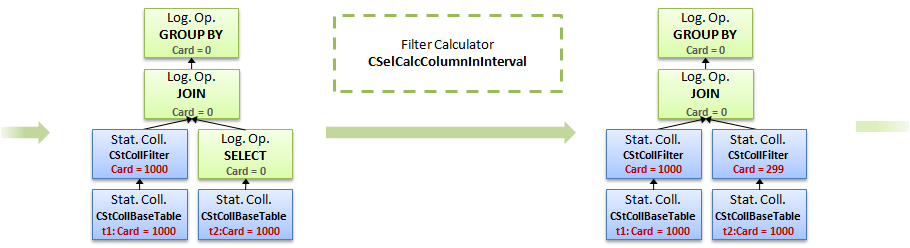
5. Теперь, есть дерево статистик фильтров по обеим колонкам, можем посчитать кардинальность соединения и статистику для группировки, применятся новый калькулятор CSelCalcExpressionToExpression

6. Наконец, используя статистику полученную на предыдущем этапе, вычисляем статистику и кардинальность группировки, используя Distinct Values Calculator — CDVCPlanJoin
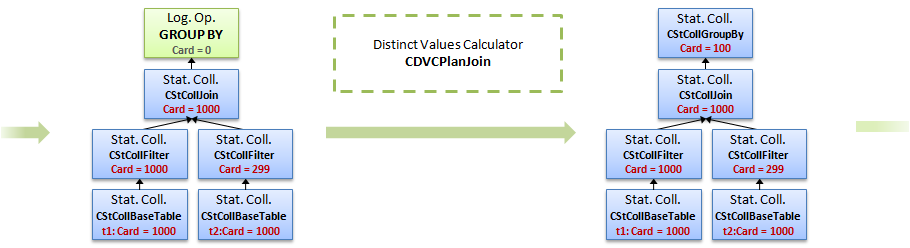
7. Наконец, кардинальность определена для всех узлов дерева
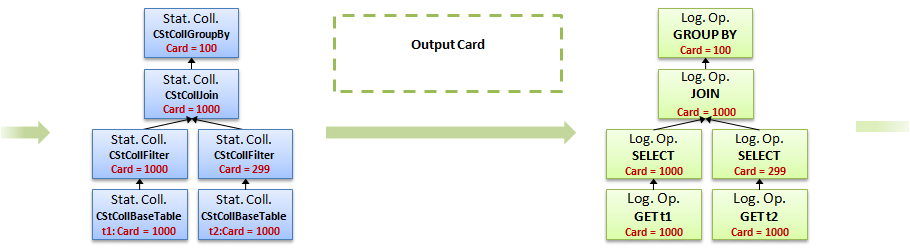
Можно начинать оптимизацию, т.е. поиск альтернатив.
Пропуская многое из вывода недокументированных флагов, что не относится к теме заметки, остановимся на том моменте, когда группировка проталкивается ниже соединения (как мы помним, в плане сначала была группировка, а соединение выполнялось уже по сгруппированным данным). Это место можно найти в выводе диагностической информации по информации о применному правилу трансформации дерева — GbAggBeforeJoin (Group By Aggregate Before Join):

Как видно из вывода флага, правило применяется к новому логическому оператору соединения, под которым находится группировка. Вернемся к иллюстрациям.
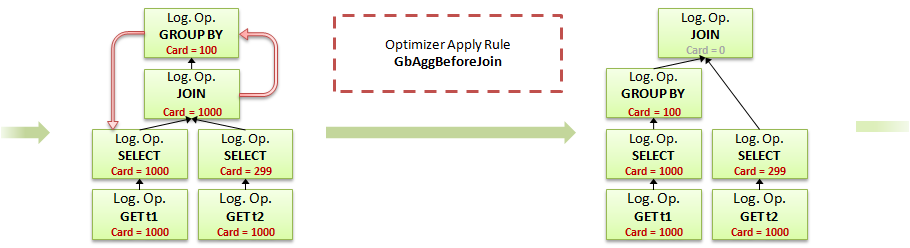
8. После применения правила, кардинальность логической операции соединения неизвестна, используется такой же подход, загружается имеющееся дерево статистик

9. Применяется тот же калькулятор CSelCalcExpressionToExpression, но т.к. теперь на левом входе статистики сгенерированные группировкой, результат получается другим.

10. После этого кардинальность вновь известна для каждого узла.
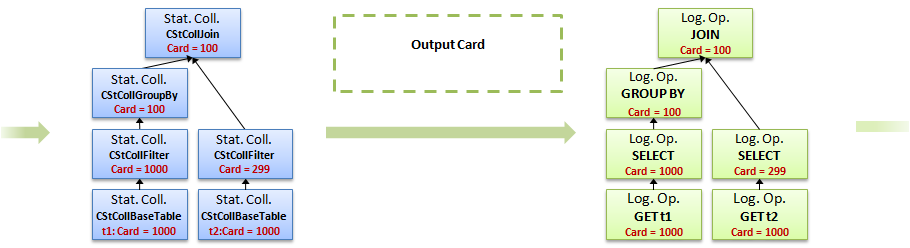
11. Можно оценить стоимость и полученная стоимость будет удовлетворять внутреннему порогу оптимизатора, значит оптимизацию можно прекращать
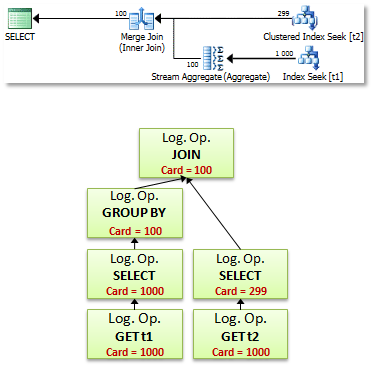
Впоследствии, «LogOp_Select+LogOp_Get» будут преобразованы в физическом дереве в «PhyOp_Filter+PhyOp»_Range, а в дереве плана просто в CXteRange с residual предикатом.
Калькуляторы 2014
Когда ясен общий процесс вернемся к алгоритмам вычисления, которые представлены в виде калькуляторов, несколько интересных из них представлены в таблице.
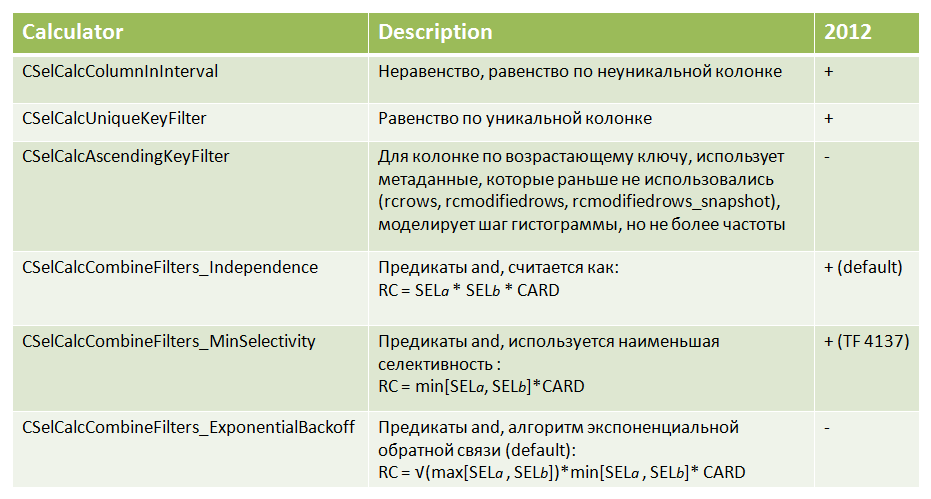
Разумеется в 2012 нет классов калькулятора, плюсики поставлены напротив алгоритмов, делающих вычисления, совпадающие с теми, что дают калькуляторы.
Некоторые интересные калькуляторы это — CSelCalcAscendingKeyFilter и CSelCalcCombineFilters_ExponentialBackoff. Впрочем, они заслуживают отдельной заметки, кстати, частично уже были описаны некоторые эксперименты, которые говорят о том, как отличается кардинальность вычисленная от 2012 версии. Ссылки на это, в конце заметки.
Что касается того, сколько всего калькуляторов, их довольно много, вот те из них, что я смог найти:

Большое поле для исследований.
Когда используется новый Cardinality Estimator 2014 (CE 2014)
Если вы соберетесь ставить эксперименты, то расскажу о еще нескольких полезных (документированных) флагах. Дело в том, что новый CE 2014 по умолчанию используется в БД с уровнем совместимости 120. Если БД имеет более низкий уровень (например, прежде чем использовать новый CE 2014, вы хотите проверить как поведет себя тот или иной запрос) , то есть флаг трассировки, который форсирует использование нового подходя на базах до 120.
И наоборот, если вы используете новый Cardinality Estimator 2014 и вас все устраивает, но в каких-то запросах проседаете, то есть флаг форсирующий старый подход. Если по какой-то причине у вас есть подозрение что включены оба флага одновременно, то есть расширенное событие которое позволяет это отследить query_optimizer_force_both_cardinality_estimation_behaviors. При этом, оптимизатор ведет себя так, как если бы ни одного флага не было использовано. Ниже приведена таблица, описывающая это поведение:
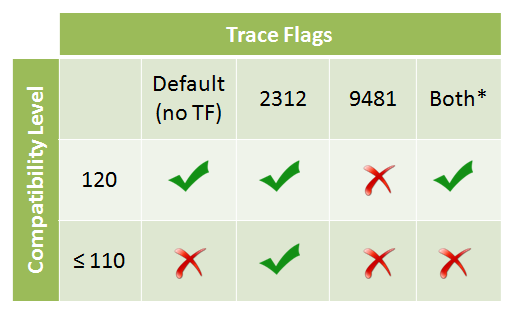
Как определить какой подход был использован
Ситуация интересная. В SQL Server 2014 CTP1, в плане было свойство CardinalityModel110, в CTP2 оно поменялось на более логичное CardinalityEstimationModelVersion. Посмотрим что будет в релизе, мое мнение, что останется версия атрибута CTP2. В любом случае, в плане нужно посмотреть на корневой псевдо оператор SELECT.
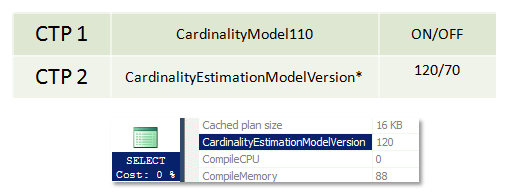
*Предупреждение:
Вы увидите это только в студии SSMS 2014! Если откроете в SSMS 2012 такого свойства просто не будет, более того если в SSMS 2012 план открыть как xml, там его тоже не будет! Видимо SSMS 2012 делает какую-то корректировку исходного XML, который она получает от сервера, в соответствии с xsd схемой и выбрасывает узлы, прямо из xml! Хотя если вы попробуете при помощи SSMS 2012 открыть план который получили запросом из sys.dm_exec_query_plan, то он откроется у вас как xml (не в графическом виде) и там будет это свойство (т.е. оно теряется, только если вы сначала посмотрите план в графическом виде)! В общем, такое поведение, очень сбивает с толку. Используйте SSMS 2014 соответствующую версии.
Заключение
На этом пока все, но есть очень много интересных тем для изучения. Например, не решатся ли MS использовать Execution Feedback, для улучшения качества оценок? Посмотрим =)
Что еще почитать на тему
В порядке размещения публикаций
2013-06-28: SQL 2014 New Cardinality Estimator
2013-07-11: SQL 2014 CTP1 — Internals do Cardinality Estimator — Parte I
2013-07-29: SQL 2014 CTP1 — Internals do Cardinality Estimator — Parte II
2013-08-04: Tracing The New Cardinality Estimation in SQL Server 2014
2013-08-13: Columnstore indexes and cardinality estimates in SQL Server 2014 CTP1
2013-11-16: A first look at the query_optimizer_estimate_cardinality XE event
2013-11-16: “CSelCalcCombineFilters_ExponentialBackoff” Calculator
2013-11-16: “CSelCalcCombineFilters_ExponentialBackoff” Calculator– Part II
2013-11-17: The CSelCalcAscendingKeyFilter Calculator
2013-11-25: Cardinality Estimation Model Version
2013-11-26: Comparing Root-Level Skews in the new Cardinality Estimator
2013-11-28: Using Legacy Methods to Lessen SQL Server 2014 Cardinality Estimator Skews




